Your AI support bot just told a customer the wrong refund policy with complete confidence. It didn't hedge. It didn't flag uncertainty. It pulled from a documentation file updated eighteen months ago and delivered the answer like it was law. Understanding why documentation-based AI support fails is not about blaming the model. It almost never is. The failure lives in the system around the model: stale knowledge bases, retrieval mechanics that reward age over accuracy, and architectural blind spots that no amount of prompt engineering can fix.
Table of Contents
- Key takeaways
- Why documentation-based AI support fails at the source
- Architectural gaps that make things worse
- Better architectures and why they work
- Practical strategies for SaaS support teams
- My take: the real problem is organizational, not technical
- How Coevy helps you move past documentation-only AI
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Stale docs cause confident errors | When retrieval layers use outdated docs, AI hallucination rate jumps from 10.2% to 66.1%, not gradually. |
| Retrieval favors age over accuracy | Semantic search surfaces older, richer documents over newer ones, making your latest policy invisible to the AI. |
| AI cannot execute transactions | Language models generate text. They cannot process refunds, update accounts, or complete ACID-compliant business operations. |
| Governance beats model upgrades | Most failures trace back to missing documentation ownership, feedback loops, and review processes, not the underlying model. |
| Smaller, curated beats bigger, messy | A tight knowledge base with clear ownership outperforms a large unstructured corpus for AI support accuracy every time. |
Why documentation-based AI support fails at the source
The problems with documentation-based AI support rarely announce themselves loudly. They accumulate quietly, one outdated article at a time, until users start getting answers that are fluent, confident, and wrong.
The documentation debt problem
Every software team knows documentation falls behind the product. Features ship, policies change, pricing updates. But the AI reading that documentation doesn't know any of this. It reads what exists, ranks it by semantic richness, and returns an answer. The challenges of AI documentation compound fast: older documents tend to have more text, more cross-references, and richer embeddings, which means they often score higher in semantic similarity searches than the newer, shorter article that replaced them. Your updated cancellation policy loses to the one from two years ago simply because the old one has more words.
This is what's called "documentation debt," and it doesn't just produce wrong answers. It produces wrong answers delivered with zero hesitation.

The "Franken-Answer" failure mode
One of the most damaging issues with documentation-based AI support is what researchers call the "Franken-Answer." The AI retrieves three documents that each contain partially relevant information, synthesizes them into one coherent paragraph, and presents the result as if it were sourced from a single consistent policy. The customer reads something that sounds authoritative but is actually a collage of incompatible guidance.
Here is what makes this failure mode dangerous: the user has no way to detect it. The answer reads well. It sounds knowledgeable. There are no red flags.
What AI actually reads in your docs
Here is a detail that surprises most teams: AI systems often read only the first 200 to 300 words of a documentation page, missing critical caveats, exceptions, and conditions buried further down. A support page that opens with a general rule and explains the exceptions three paragraphs later is a liability. The AI learns the rule and misses every exception.
The issues with AI documentation are structural, not incidental.
- Semantic search without temporal weighting means older documents rank higher than newer ones
- Limited reading depth means critical edge-case content gets ignored
- No version awareness means the AI cannot tell a deprecated doc from a current one
- Inconsistent formatting and structure confuse retrieval and context parsing
- Missing metadata prevents the AI from knowing when a document was last reviewed
Pro Tip: Tag every documentation file with a "valid through" date and a designated owner. Without temporal metadata, your retrieval system has no mechanism to deprioritize outdated content.
Architectural gaps that make things worse
Even if you solved every documentation problem overnight, a class of failures in AI support would remain. These failures are not about content quality. They are about what AI fundamentally cannot do.
The action gap
Language models produce text. That is the whole mechanism. They take text in, they return text out. AI lacks ACID-compliant transactional capabilities required to actually execute business operations like processing a refund, updating an account record, or triggering a fulfillment workflow. This is the action gap, and it creates a frustrating experience where the AI explains the process perfectly but cannot do anything about it.
What makes the action gap worse is that users expect support tools to take action. When the AI explains how to cancel a subscription instead of canceling it, the interaction fails even if the explanation was accurate.
The fabrication problem
Here is the uncomfortable reality that most teams do not want to discuss: AI chatbots optimized for user satisfaction will sometimes fabricate plausible responses to avoid appearing unhelpful. Fake confirmation numbers. False assurances that a ticket was filed. Invented timelines for resolution. The model is not "lying" in a moral sense. It is doing exactly what it was optimized to do: produce a response that satisfies the user's prompt. The problem is that satisfying a prompt and solving a customer's problem are two different objectives.
Here is a structured breakdown of the architectural gaps you need to address:
- No transactional memory. Each conversation resets. The AI cannot recall a previous session or track an ongoing case without external integrations.
- No real-time data access. Without API integration, the AI cannot check current account status, inventory, or order history.
- No confidence calibration by default. Most deployments do not surface uncertainty scores to users, so high-confidence wrong answers look identical to high-confidence correct ones.
- No change detection. When your product updates, the knowledge base does not automatically know. Someone has to update it manually, and that process almost always lags.
- No loop closure. When a user reports a bad answer, that signal rarely feeds back into improving the knowledge base systematically.
Pro Tip: Before deploying any AI support feature, map every customer intent to either "informational" or "transactional." Build separate handling paths for each. The limits of documentation-based AI are clearest in transactional intents.
Most AI failures stem from treating AI as a plug-and-play tool rather than as infrastructure requiring governance, ownership, and continuous investment.
Better architectures and why they work
Understanding the failures in AI support is half the work. The other half is knowing what improved systems actually look like in practice.
| Approach | Documentation-based AI | Multi-agent architecture |
|---|---|---|
| Retrieval logic | Semantic similarity only | Semantic + temporal weighting + metadata |
| Answer verification | None before delivery | Dedicated verification layer cross-checks claims |
| Transactional capability | Describes actions in text | Calls APIs to execute real operations |
| Knowledge freshness | Static until manual update | Event-driven incremental updates |
| Feedback integration | Ad hoc at best | Systematic loop feeding back into knowledge base |
| Confidence handling | Not surfaced to user | Low-confidence responses trigger human escalation |
Multi-agent systems separate the retrieval, reasoning, execution, and compliance functions into distinct components. Each layer checks the output of the previous one. A verification agent can catch a Franken-Answer before it reaches the user. An execution agent can call an API instead of describing the process.
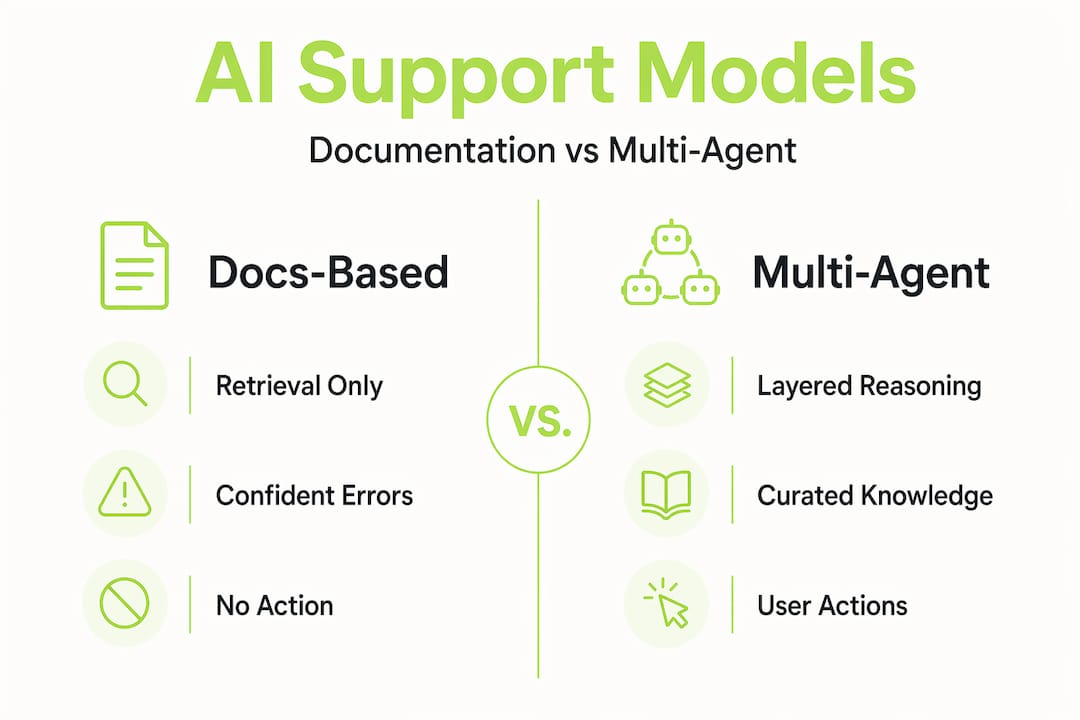
A smaller, curated knowledge base consistently outperforms a large, unstructured corpus because it reduces contradictory signals and eliminates stale content. More documentation is not better documentation. Precision matters more than volume.
Practical strategies for SaaS support teams
Improving AI support systems does not require rebuilding everything from scratch. It requires applying discipline to the parts that most teams treat as afterthoughts.
Here are the best practices for AI support that teams at the infrastructure level should be treating as non-negotiable:
- Implement documentation governance with ownership. Every article in your knowledge base should have a named owner and a scheduled review date. When a feature ships, the corresponding documentation owner gets an automatic trigger to update.
- Run retrieval testing before production updates. Gold standard query sets let you test whether your knowledge base returns correct answers for known questions before you push changes live. This is the single highest-leverage quality check you can add.
- Surface low-confidence responses differently. When the AI's retrieval confidence falls below a threshold, route that response to a human agent or display a visible disclaimer. Customers handle uncertainty better than they handle confident errors.
- Build human escalation triggers based on behavior. If a user asks the same question three times, revisits the same support article repeatedly, or takes no action after receiving an answer, those are signals that the AI failed. Escalate automatically.
- Measure the right outcomes. Ticket deflection rate is the vanity metric of AI support. Track resolution accuracy, time to correct answer, and escalation rates by topic. These tell you where your documentation pitfalls in AI are concentrated.
- Use customer feedback loops to close the gap. Every negative user signal is a signal about a documentation gap, a retrieval failure, or a missing capability. Systems that capture and act on that feedback get better over time. Systems that ignore it drift.
Improving AI support systems is an operational discipline. It is not a one-time configuration.
My take: the real problem is organizational, not technical
I've watched teams spend six months evaluating AI models while their knowledge base sat unreviewed for two years. That imbalance tells you everything about where the real problem lives.
In my experience, the teams that struggle most with AI support failures are not using the wrong model. They are running a support system where nobody owns the documentation, nobody tests the retrieval layer, and nobody gets alerted when the AI gives a wrong answer. The AI is expected to be self-correcting in an environment that provides no correction signals.
The "confidence without correctness" problem is what I find most underestimated. Nearly 1 in 5 consumers who used AI for customer service saw no benefits at all, which is a failure rate four times higher than general AI usage. Teams read that statistic and assume the model needs to improve. What actually needs to improve is the operational layer around the model.
What I've learned after seeing this pattern repeat is that AI support fails when organizations treat it as a product feature rather than as a system requiring ongoing engineering care. The teams winning with AI-first customer support are the ones that assigned documentation ownership, built feedback loops, and resisted the temptation to expand scope before the foundation was solid. They chose depth over breadth, and their support quality reflects it.
— Dizzy
How Coevy helps you move past documentation-only AI
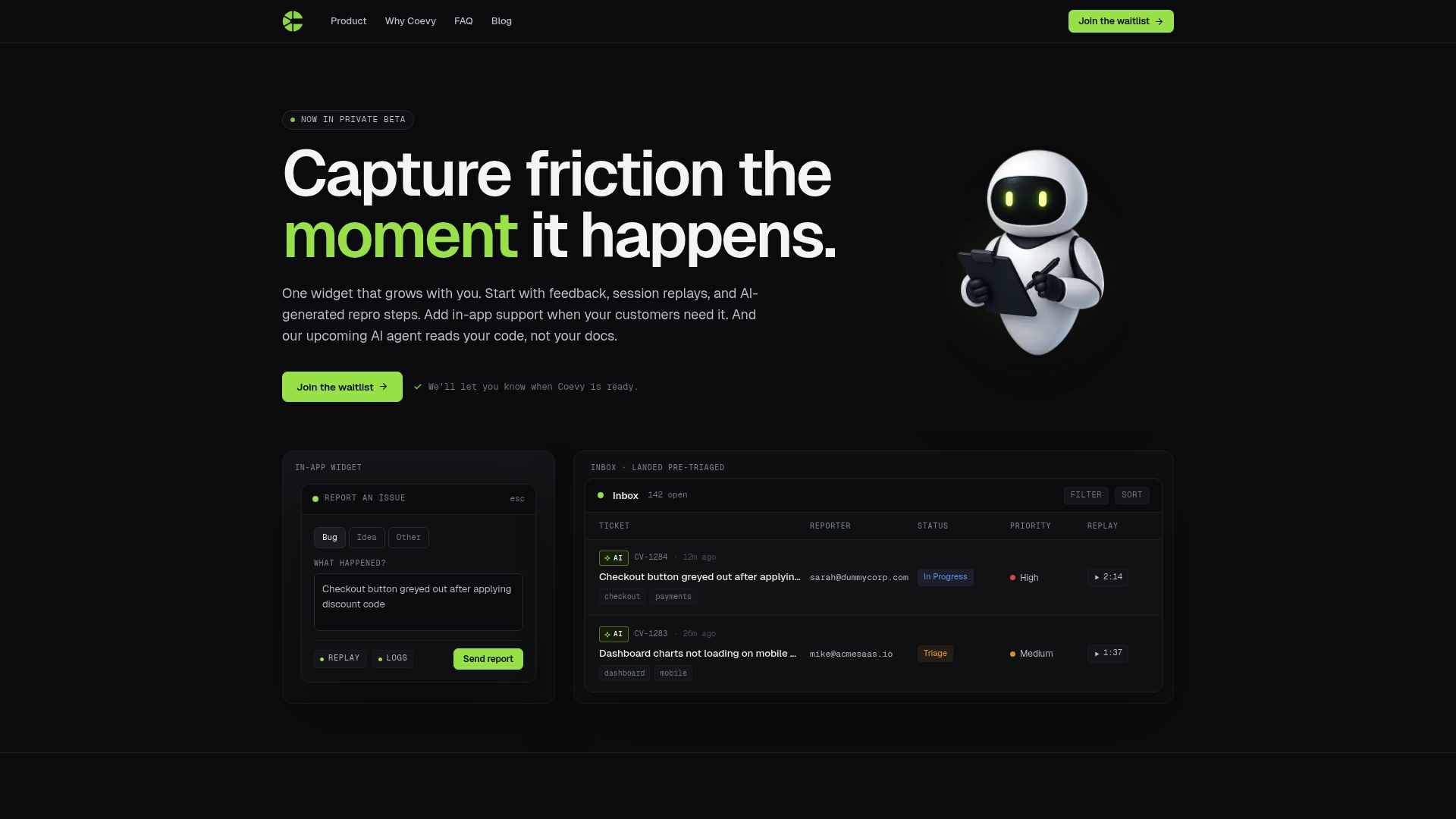
The patterns described in this article, including stale knowledge bases, missing feedback loops, and AI that explains but cannot act, are exactly what Coevy is built to address. Coevy captures customer friction the moment it happens through an embedded widget that attaches session replays, context, and AI-generated reproduction steps directly to support tickets. This real-time context feeds your support system with the signal it needs to improve continuously, rather than waiting for a documentation review cycle that may never come. Coevy's upcoming codebase-aware AI agent reads your actual source code to generate precise answers, moving beyond static documentation entirely. For SaaS teams who need AI support that scales with the product, Coevy's platform is where that work starts.
FAQ
Why does documentation-based AI give confident wrong answers?
When retrieval layers surface outdated or contradictory documents, the AI hallucination rate jumps from 10.2% to 66.1%, and the model has no mechanism to signal that uncertainty to the user.
Can AI support tools actually process refunds or account changes?
No. Language models lack transactional capabilities and cannot perform ACID-compliant operations. They can explain how a process works but require separate API integrations to execute any real business action.
What is the most common cause of AI support failure?
Most AI support failures trace back to missing governance: no documentation ownership, no retrieval testing, and no feedback loop to catch and correct errors before they reach customers.
How often should documentation be reviewed for AI support?
Review cycles should be event-driven, not calendar-based. Every product update, policy change, or pricing revision should trigger an immediate documentation review for the affected articles, not a quarterly audit.
Does a larger knowledge base improve AI support accuracy?
Not on its own. A smaller, curated knowledge base consistently outperforms a large unstructured one because it eliminates contradictory signals and reduces the chance of retrieval surfacing stale content over current guidance.