
Context-aware AI is defined as a system that retrieves live, structured data at inference time to generate answers tailored to a specific user's situation, product state, and interaction history. Static FAQs, by contrast, are fixed knowledge bases that return the same cached response regardless of who is asking or what they have already tried. For product managers and customer support professionals, this distinction is not academic. It determines whether your support system resolves issues or just delays them. Retrieval-augmented generation (RAG) and platforms like Coevy are making context-aware support the new baseline, and the gap between the two approaches is widening fast.
Why context-aware AI beats static faqs on accuracy
The most measurable advantage of context-aware AI over static FAQs is hallucination reduction. Dynamic context retrieval at inference reduces AI hallucinations by up to 37% compared to static baselines. That number matters because a hallucinated answer in a support context does not just fail to help. It actively erodes user trust and creates more tickets downstream.
Static FAQs suffer from what practitioners call context drift. The knowledge base is accurate on the day it is published, then slowly becomes stale as products change, pricing updates, and edge cases multiply. The FAQ does not know it is wrong. It returns confident answers based on outdated information, and neither the user nor the support agent gets a signal that something has failed.
Context-aware AI solves this by pulling live data at the moment of the query. A RAG-based system, for example, retrieves the current version of a document, the user's account status, and their recent session activity before generating a response. The answer reflects reality, not a snapshot from three months ago.
- Static FAQs return the same answer to every user regardless of account state
- Context-aware AI incorporates customer-specific data, recent interactions, and live business rules
- Fine-tuning alone cannot provide access to live runtime data such as current inventory or customer-specific state
- Dynamic retrieval keeps answers synchronized with product changes without manual FAQ updates
Pro Tip: Set up a monitoring pipeline that flags responses where the retrieved context and the generated answer diverge significantly. This is your earliest signal of context poisoning before it reaches users at scale.
How does context-aware AI improve support outcomes?
The user experience gap between contextual assistance and static FAQ responses shows up most clearly in resolution speed. Context-aware frameworks significantly improve straight-through processing rates, enabling faster resolution of complex support exceptions without human intervention. Straight-through processing means the issue is identified, addressed, and closed without a human ever touching it. Static FAQs cannot achieve this because they cannot take action. They can only display text.

Consider a SaaS user who hits a payment failure at checkout. A static FAQ returns a generic article about billing. A context-aware AI agent reads the user's account tier, their recent failed transaction, the error code from the session, and the current state of the payment gateway. It then either resolves the issue directly or routes the ticket with a pre-populated summary. The user's experience is completely different.
Here are four concrete improvements that context-aware AI delivers over static FAQs:
- Personalized responses based on the user's actual account data, not generic documentation
- Governed actions such as issuing a refund, resetting a password, or escalating with full context attached
- Audit trails with full traceability of data sources, rules, and reasoning steps, which static FAQs cannot provide
- Reduced escalations because the AI handles complex exceptions autonomously rather than deferring every edge case to a human agent
| Capability | Static FAQ | Context-Aware AI |
|---|---|---|
| Personalization | None | Full account and session context |
| Action capability | Display only | Governed actions with audit trail |
| Accuracy over time | Degrades as product changes | Stays current via dynamic retrieval |
| Complex exception handling | Fails or escalates | Resolves autonomously |
What are the real limitations of static faqs?
Static FAQs fail in predictable ways, and most support teams already know the symptoms. Users report that the FAQ "didn't help." Ticket volume stays high despite published documentation. Agents spend time answering questions that the FAQ was supposed to handle. These are not content quality problems. They are structural problems.
The deeper issue is that static knowledge bases cannot distinguish between users. A new user asking about onboarding and a power user hitting an API rate limit get the same FAQ article. The system has no memory of what the user already tried, no awareness of their plan tier, and no connection to live product data.
Naive AI implementations create a different but equally serious problem: context poisoning. Irrelevant or conflicting data in the AI input leads to silent failures, where the model produces confident but incorrect responses. This happens when teams dump entire knowledge bases into prompts without filtering for relevance to the specific query.
- Overloaded prompts cause the model to over-index on irrelevant information
- Extra context can degrade output quality by introducing competing relevance signals that confuse agent behavior
- Static FAQs have no mechanism to flag when their content is outdated or contradicted by live product state
- Neither static FAQs nor poorly scoped AI implementations provide traceability for regulated industries
Pro Tip: Before expanding your AI's context window, measure the impact on answer quality using a held-out test set of real support queries. More data in the prompt does not automatically mean better answers. Relevance filtering is the variable that matters.
How should teams implement context-aware AI in support workflows?
The most effective architecture for production AI support combines two layers. Static governance rules enforce behavioral constraints and compliance requirements. A dynamic retrieval layer supplies live data, current documentation, and user-specific context at inference time. Neither layer works well without the other.

High-performing organizations invest roughly twice as much in context foundations as in AI tooling itself, allocating around 60% of AI budgets to data quality, governance, and semantic layers rather than model tuning. This allocation reflects a hard-won lesson: the model is rarely the bottleneck. The quality and structure of the context it receives determines output quality.
Pro Tip: Version-control your context sources the same way you version-control your codebase. When an AI response degrades, you need to know exactly which context document changed and when. Without version history, debugging context drift is nearly impossible.
Here is a practical implementation checklist for support and product teams:
| Practice | Why It Matters |
|---|---|
| Separate static governance from dynamic retrieval | Prevents compliance rules from being overridden by live data conflicts |
| Filter context by query intent before retrieval | Reduces context poisoning and improves answer precision |
| Version-control all context sources | Enables root-cause analysis when output quality drops |
| Monitor straight-through processing rates | Quantifies the business impact of context quality improvements |
| Audit AI reasoning trails regularly | Meets regulatory requirements and catches silent failures early |
Structured runtime context enables AI to incorporate customer-specific data, dynamic business rules, and recent interactions that fine-tuning alone cannot achieve. This is the architectural insight that separates teams getting real results from teams that are still debating which model to use. The model choice matters far less than the quality of the context you feed it.
For teams handling repetitive support questions, the dynamic retrieval layer also reduces the maintenance burden. Instead of manually updating FAQ articles every time a feature changes, the AI pulls from live documentation and session data automatically.
Key takeaways
Context-aware AI outperforms static FAQs because it retrieves live, structured data at inference time, reducing hallucinations by up to 37% and enabling governed actions that static knowledge bases cannot perform.
| Point | Details |
|---|---|
| Hallucination reduction | Dynamic retrieval cuts AI errors by up to 37% compared to static baselines. |
| Context quality over model size | Allocate budget to data quality and semantic layers before investing in larger models. |
| Static FAQs degrade over time | Fixed knowledge bases become inaccurate as products change, with no built-in correction signal. |
| Two-layer architecture wins | Combine static governance rules with a dynamic retrieval layer for production-grade AI support. |
| Measure before expanding context | Adding more data to prompts can worsen outputs. Filter by relevance and track quality metrics. |
The shift nobody talks about enough
Most conversations about AI in support focus on which model to pick. GPT-4o versus Claude 3.5 Sonnet versus Gemini. That debate misses the point almost entirely. After working through dozens of support AI implementations, the pattern is consistent: teams that obsess over model selection while neglecting their context layer consistently underperform teams that invest in data quality and retrieval architecture, even when the latter use smaller, cheaper models.
The economic case for context foundations is also stronger than most teams realize. A well-built context fabric is portable. When a better model releases, you swap the model and keep the context infrastructure. Teams that skipped this investment have to rebuild from scratch every time the AI market shifts.
What I find most underappreciated is the governance angle. Context-aware AI with full audit trails is not just more accurate. It is defensible. In regulated industries like fintech and healthcare SaaS, being able to show exactly which data source drove a specific AI response is the difference between a compliant system and a liability. Static FAQs offer none of that traceability.
The teams winning with AI support right now are not the ones with the biggest models. They are the ones who treated context engineering as a first-class discipline, measured its impact rigorously, and built retrieval pipelines that stay synchronized with their actual product. That is the shift worth making in 2026. You can learn more about how AI surfaces product signals from live user interactions to keep that context layer sharp.
— Dizzy
See context-aware support in action with Coevy
Coevy is built on the principle that support AI is only as good as the context it receives. The platform captures friction the moment it happens, attaching session replays, auto-tagged feedback, and AI-generated bug reproduction steps directly to every support ticket. That means your AI agent works from real, structured context rather than guessing from a generic knowledge base.
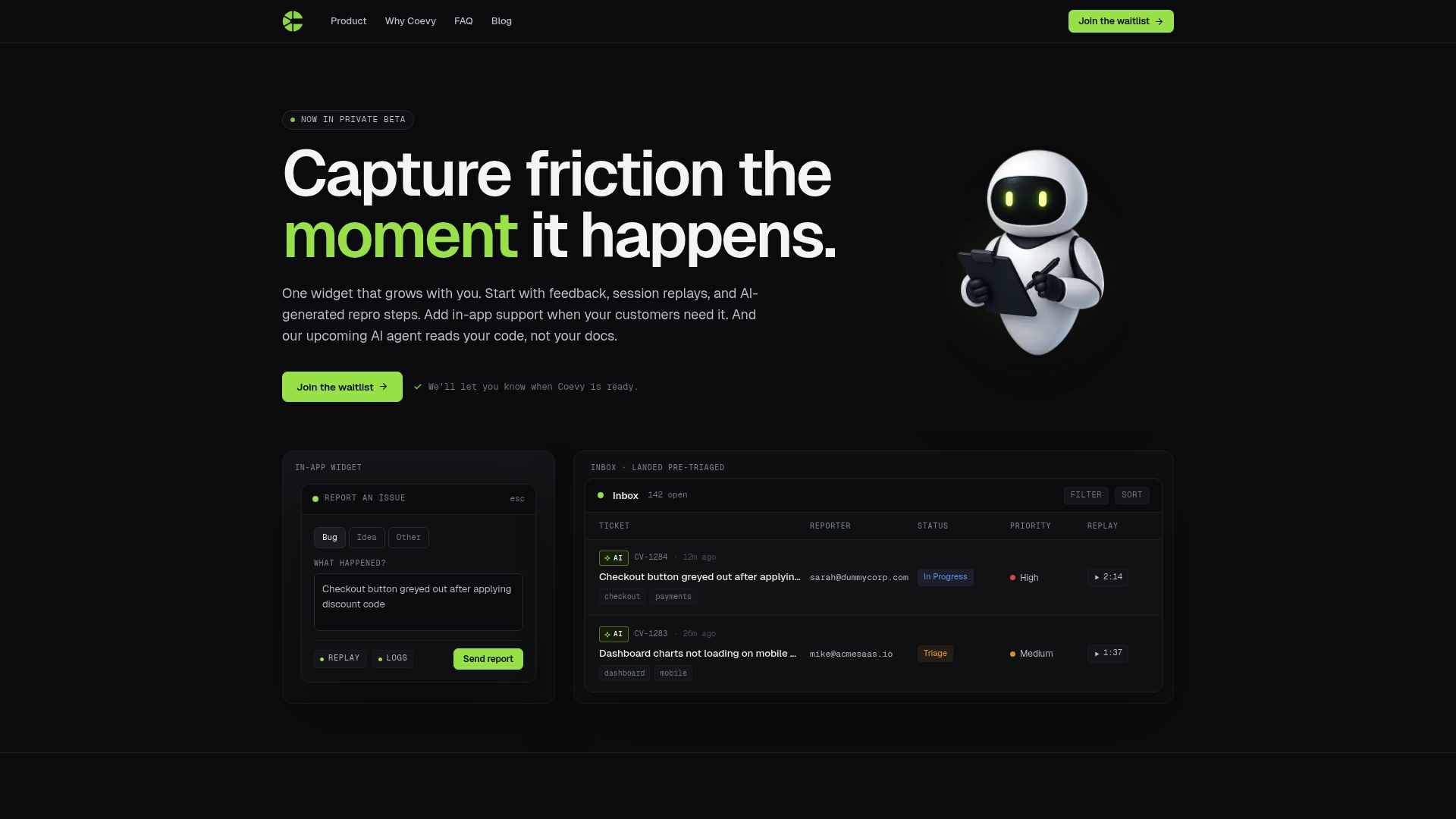
Coevy's codebase-aware AI agent reads your actual source code to generate precise answers, not documentation summaries. For product and support teams ready to move beyond static FAQs, Coevy's platform connects live user context to every support interaction from day one. If you want to understand how an AI agent can handle the full range of user questions at scale, Coevy is built to show you exactly that.
FAQ
What is context-aware AI in customer support?
Context-aware AI is a system that retrieves live user data, session history, and business rules at the moment of a query to generate a relevant, personalized response. Unlike static FAQs, it adapts its answer based on who is asking and what they have already experienced.
How much does context-aware AI reduce hallucinations?
Dynamic context retrieval at inference reduces AI hallucinations by up to 37% compared to static knowledge base approaches. That reduction comes from grounding responses in current, structured data rather than cached or pre-trained information.
Why do static faqs fail for complex support issues?
Static FAQs return the same answer to every user regardless of account state, product version, or prior interactions. They cannot take governed actions, cannot access live data, and provide no audit trail, making them structurally unsuitable for complex or regulated support scenarios.
What is context poisoning and why does it matter?
Context poisoning occurs when irrelevant or conflicting data is fed into an AI prompt without intent-aware filtering, causing the model to produce confident but incorrect responses. It is one of the most common failure modes in naive AI support implementations and is invisible without active monitoring.
How should product teams budget for context-aware AI?
High-performing organizations allocate around 60% of their AI budgets to context foundations including data quality, governance, and semantic layers rather than model selection or fine-tuning. Investing in the retrieval layer delivers more durable returns than upgrading to a larger model.