
Your backlog has 300 open bugs. Three engineers. A release in two weeks. Sound familiar? The role of AI in bug prioritization has shifted from experimental curiosity to a practical necessity for software teams drowning in issue volume. But there's a persistent misconception worth addressing upfront: AI does not replace the human judgment required for complex triage decisions. What it does is handle the classification, routing, and severity scoring that currently eats hours of your team's week, so engineers and product managers can focus on the decisions that actually require context. This article breaks down exactly how that works in 2026.
Table of Contents
- Key takeaways
- How AI classifies, routes, and prioritizes bugs
- AI vs. manual triage: what the data actually shows
- Advanced AI techniques that sharpen prioritization
- Integrating AI into your existing workflows
- Common pitfalls to avoid
- My honest take on AI and human judgment in triage
- How Coevy helps teams act on bugs faster
- FAQ
Key takeaways
| Point | Details |
|---|---|
| AI assists, not replaces | AI automates classification and routing while humans retain final authority on critical bug decisions. |
| Speed gains are measurable | AI triage systems reduce median resolution time from days to hours when combined with human review. |
| Multimodal inputs outperform text alone | Including screenshots alongside text improves severity classification accuracy over text-only models. |
| Confidence thresholds prevent silent errors | Set explicit AI confidence cutoffs so low-certainty cases automatically escalate to a human reviewer. |
| Data quality drives model performance | AI prioritization is only as reliable as the bug reports and historical data you feed it. |
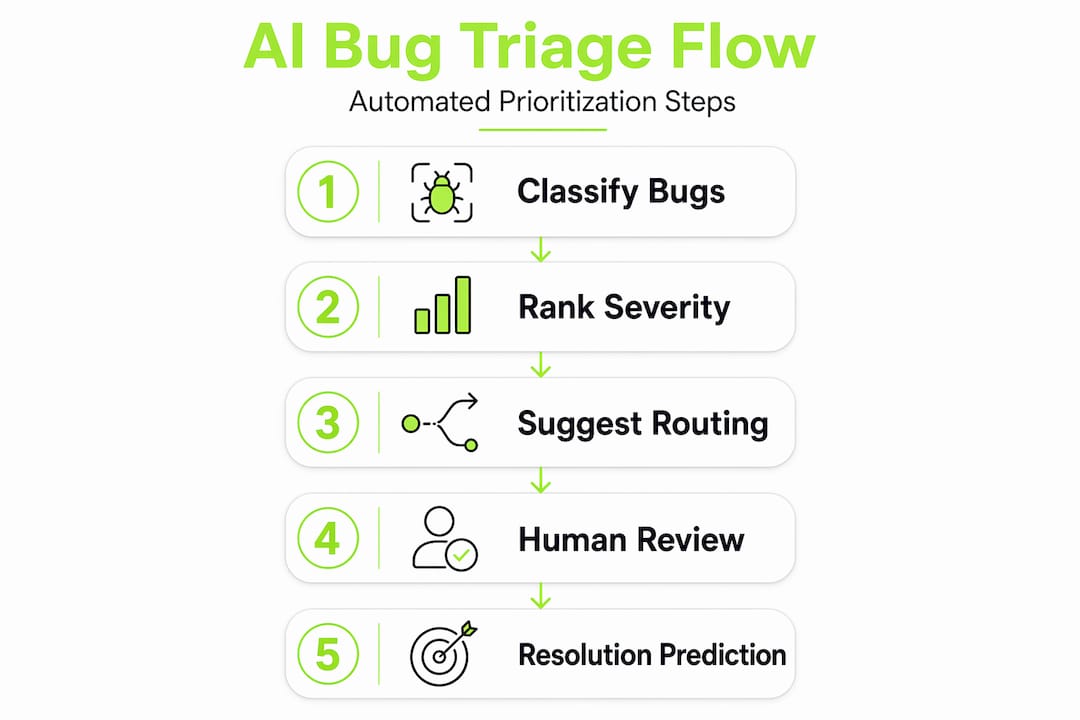
How AI classifies, routes, and prioritizes bugs
Automated bug triage, the industry term for what most people loosely call "AI bug prioritization," refers to using machine learning and natural language processing to sort, score, and assign incoming bug reports without manual intervention. It is not one single tool. It is a pipeline with distinct stages, and understanding each stage helps teams set realistic expectations.
The first stage is classification. NLP models parse the text of a bug report and map it to a component, feature area, or team. The second stage is severity scoring, where the model estimates impact based on keywords, user data, and historical patterns. The third stage is routing, where the classified and scored bug gets assigned to the right developer or queue.
Real systems running today show what this pipeline can achieve in practice:
- Miro's BugManager built on Amazon Bedrock achieves top-3 routing accuracy of 95% when paired with a human making the final selection, with classification completing in about 53 seconds.
- The open source triage-iq pipeline handles component classification, duplicate detection, and resolution time prediction in under 4 seconds, outputting a structured JSON triage plan your tooling can consume directly.
- Debian maintainers use AI primarily for duplicate detection and routing, but explicitly keep humans responsible for final decisions, particularly in security-sensitive cases.
The key architectural decision most successful teams make is building a "human-in-the-loop" model. AI generates a ranked suggestion with a confidence score. If that score clears a defined threshold, the system auto-routes. If it does not, a human reviewer picks from the AI's top candidates. This keeps the speed benefit without handing over full autonomy to a model that has never shipped software.
Pro Tip: Label your AI routing suggestions visibly in your issue tracker. When engineers see "AI suggested: Team A (confidence: 91%)" rather than a silent auto-assignment, they trust the system faster and catch edge cases more reliably.
AI vs. manual triage: what the data actually shows
The honest comparison between AI-assisted and purely manual bug prioritization techniques is not one-sided. Each approach has real strengths and meaningful gaps.
| Factor | Manual triage | AI-assisted triage |
|---|---|---|
| Speed | Hours to days per cycle | Seconds to minutes per report |
| Consistency | Varies by reviewer experience | Consistent once model is trained |
| Contextual judgment | Strong for novel or complex bugs | Weak without sufficient training data |
| Scalability | Degrades under high bug volume | Handles volume spikes well |
| Explainability | Naturally transparent | Requires additional tooling (e.g., LIME) |
| Reassignment rate | High when routing is unclear | Lower with confidence thresholds applied |
Manual triage suffers most at scale. When bug volume spikes, after a major release or during a high-traffic incident, human reviewers slow down, make more routing errors, and create reassignment cycles that delay resolution. AI handles that volume spike without degrading.
The limitation on the AI side is organizational context. Models trained on six-month-old data do not know that your team restructured last quarter, or that a new service just launched. That blind spot causes misrouting in ways that are harder to catch than a human reviewer making an obvious mistake.
Pro Tip: Retrain or fine-tune your triage model every time your team structure, product areas, or SLA definitions change significantly. Stale models quietly degrade routing accuracy before anyone notices.
Advanced AI techniques that sharpen prioritization
Beyond basic classification, machine learning for bug tracking has matured to include capabilities that give teams much richer signals for scheduling and planning.

Severity prediction with transformer models
Transformer-based NLP architectures like DeBERTa can predict bug severity with over 80% accuracy using explainable AI methods such as LIME to surface which words in a report drove the prediction. That explainability detail matters enormously for team trust. Engineers do not adopt black-box systems. When a model can show "this was flagged critical because the phrase 'data loss' appeared with 'production environment,'" developers validate and accept the output instead of overriding it reflexively.
Duplicate detection
Duplicate bugs are a real tax on engineering time. When the same crash gets filed by 40 users independently, someone has to recognize those are all the same root cause. AI models trained on past duplicates detect similarity through vector embeddings and can cluster related reports automatically, collapsing what might be 40 tickets into one canonical issue.
Resolution time prediction
The triage-iq system outputs a predicted resolution window alongside its classification, achieving a mean absolute error of 3.4 days on the VS Code dataset. That number feeds directly into sprint planning. If the model says a P2 bug has an expected resolution of 1 day, it gets slotted differently than one projected at 8 days.
Multimodal inputs
Text alone misses a lot. Experiments with vision-based triage show that image-only fine-tuned models outperform text-only models in multiclass severity classification. Screenshots capture UI states, error overlays, and visual regressions that a user's written description never fully conveys. Teams feeding both text and screenshots into their triage pipeline get more accurate severity scores as a result.
Combining these capabilities produces something closer to a fully structured triage output. A well-designed AI triage system does not just assign a priority label. It returns a complete structured triage plan with predicted component ownership, expected resolution window, and suggested next steps. That format is what makes AI outputs genuinely usable rather than one more signal engineers have to interpret manually.
Integrating AI into your existing workflows
Knowing AI can classify and score bugs is useful. Knowing how to wire that into your existing processes is where teams actually see results. Here is a practical sequence for integration:
Map AI output fields to your existing priority schema. If your issue tracker uses P0 through P4, your AI model needs to output scores in those exact terms, not abstract confidence percentages that someone has to translate at 9 a.m. during a sprint planning meeting.
Define confidence thresholds before you go live. Routing below 85% confidence to a human reviewer is a reasonable starting point. Conservative auto-prioritization reduces risk while you build confidence in the model's outputs.
Integrate via APIs and work item query languages. For teams using Azure Boards, cross-functional triage meetings involving project owners, team leads, and business analysts can consume AI-generated triage data through stable API connections rather than manual imports. The AI automation integration guide for IT leaders covers the technical setup for connecting triage pipelines to existing trackers at scale.
Add a Slack or notification layer for escalated bugs. When the AI flags a bug as critical but confidence is below threshold, route an alert to the relevant team lead immediately. Do not let uncertain high-severity cases sit in a queue.
Run a weekly calibration review for the first 90 days. Pull the bugs where AI routing disagreed with the final human decision. Use those cases to improve training data or adjust thresholds. Teams that skip this step find their models drifting within two quarters.
AI-generated issue summaries can also reduce the manual prep work before triage meetings, giving reviewers a concise digest of each report rather than a raw text dump from a user's browser.
Common pitfalls to avoid
Deploying AI for bug prioritization fails in predictable ways. Most teams hit at least one of these:
- Treating high confidence scores as certainty. A 92% confidence score means the model was right in 92 of 100 similar cases during training. That 8% failure rate compounds across hundreds of daily reports.
- Skipping transparency with the engineering team. Models adopted without explanation create distrust. Engineers who do not understand why a bug was routed to them push back, override frequently, and generate bad feedback loops that degrade model quality.
- Ignoring data quality at ingestion. AI triage models trained on poorly written bug reports with inconsistent severity labels will reproduce those inconsistencies at scale. The automation amplifies whatever is already in your data.
- Failing to update context for organizational changes. AI assists mainly in administrative triage tasks, and human expertise remains vital when product teams shift, new services launch, or security context changes.
- Testing only text inputs when multimodal is available. If your users can attach screenshots, and most modern bug reporters let them, run a direct comparison between text-only and combined inputs before committing to a model architecture.
Pro Tip: Build an explicit escalation protocol into your triage workflow from day one. Any bug where the AI confidence is below your threshold AND the severity is P0 or P1 should immediately notify a human, not wait in the review queue.
My honest take on AI and human judgment in triage
I've worked with enough software teams integrating AI into their QA processes to have a clear opinion: the biggest failure mode is not under-trusting AI. It's over-trusting it at exactly the wrong moment.
I've seen teams automate their entire critical bug routing pipeline and then scramble when a security vulnerability got mislabeled as a UX issue because the model had never seen that CVE pattern before. The AI impact on QA processes is real and measurable. But it shows up most reliably in the volume work: the duplicate detection, the component routing, the resolution time estimates. The judgment calls about whether a bug should block a release? That still needs a human who understands what's riding on that ship date.
What I'd tell any product manager or engineering lead right now: use AI to cut your triage time by 60 to 70 percent on the routine cases. Invest the time you save into better human review of the edge cases. The teams I've seen get the most out of prioritizing bugs with AI are the ones who treat the model as a very fast, very consistent junior analyst rather than an autonomous decision-maker. The model never gets tired at 11 p.m. before a release. That's valuable. It also doesn't know that your biggest enterprise customer is on the affected endpoint. That's where you still earn your salary.
The uncomfortable truth is that most teams underinvest in the feedback loop. They deploy, see accuracy numbers improve, and stop reviewing disagreements. Six months later the model is quietly wrong about a whole new category of bugs and nobody noticed until a P1 slipped through. Build the review cadence in from the start and protect it like any other engineering ritual.
— Dizzy
How Coevy helps teams act on bugs faster
If you are evaluating AI tools for bug prioritization, Coevy is worth a close look. The platform captures bugs with full session context attached automatically, including replays and AI-generated reproduction steps, so the data feeding your triage process is richer from the moment a report is created. Coevy's AI auto-tagging and prioritization features work on reports as they come in, and its codebase-aware AI support reads your actual source code rather than relying on documentation, which means severity assessments reflect real application behavior. For teams building toward a more automated QA workflow, you can explore Coevy's platform and see how it fits your existing issue tracking and support setup.
FAQ
What is the role of AI in bug prioritization?
AI automates the classification, severity scoring, and routing of bug reports using machine learning and natural language processing. It reduces manual triage time significantly while supporting human reviewers in making final prioritization decisions.
Can AI fully replace human judgment in bug triage?
No. AI handles volume and consistency well but lacks the organizational context and domain knowledge needed for complex or security-sensitive decisions. Human validation remains critical, especially for high-severity issues.
How accurate are AI bug triage systems?
Accuracy varies by system and training data. BugManager achieves top-3 routing accuracy of 95% when paired with human selection, while severity prediction models using DeBERTa reach around 82% accuracy.
What confidence threshold should trigger human review?
Routing below 85% confidence to a human reviewer is a widely recommended starting point. Any critical bug below that threshold should trigger an immediate notification rather than waiting in a standard queue.
Does including screenshots improve AI bug prioritization?
Yes. Multimodal triage systems that incorporate screenshots alongside text descriptions outperform text-only models in severity classification accuracy, capturing visual context that written reports often miss.