
Your AI support bot confidently tells a user that a certain API endpoint accepts a "userId` parameter, but your codebase removed that field three releases ago. The user follows the advice, hits an error, and files another ticket. That cycle, repeated across dozens of interactions, erodes trust faster than any outage. The root cause is almost never the language model itself. It's the absence of real source code context feeding into the system. This guide walks software teams and support managers through a production-ready pipeline to ingest source code, ground AI responses in actual evidence, and dramatically cut the hallucination rate that makes AI support unreliable.
Table of Contents
- Why ingesting source code matters for AI support accuracy
- Essential tools and requirements for code ingestion pipelines
- Step-by-step guide to ingesting source code for AI support
- Troubleshooting and handling edge cases in code ingestion
- Evaluating pipeline accuracy: Metrics and ongoing verification
- Why retrieval and grounding matter more than model size
- Get started with accurate, AI-powered support
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Grounding reduces errors | Accurate AI support is only possible when responses are grounded in real code context. |
| Hybrid retrieval is vital | Combining semantic and lexical search methods delivers precise answer matching. |
| Ongoing evaluation needed | Support teams must regularly measure retrieval quality and answer faithfulness for sustained pipeline accuracy. |
| Handle edge cases proactively | Update indexes and manage permissions to avoid issues like stale knowledge or evidence gaps. |
Why ingesting source code matters for AI support accuracy
When an AI support system lacks direct access to your codebase, it operates on whatever it was trained on: general programming knowledge, outdated documentation, or scraped content that may not reflect your product at all. The result is confident-sounding answers that are factually wrong for your specific application.
The operational consequences stack up quickly:
- Increased ticket volume: Users who receive wrong answers file follow-up tickets, doubling the load on your support team.
- Eroded user trust: A single confident but wrong answer can make users question every future AI response.
- Developer time waste: Engineers get pulled into debugging sessions caused by AI-generated misinformation rather than actual bugs.
- Slower resolution cycles: Without grounded context, support agents spend more time verifying AI suggestions before acting on them.
The fix is grounding. Empirical-style comparisons show that grounding AI responses in retrieved evidence can materially reduce hallucinations and improve response accuracy for customer support, which is exactly what code ingestion enables inside a retrieval-augmented generation (RAG) pipeline.
The numbers tell a compelling story:
| Metric | Without code ingestion | With code ingestion |
|---|---|---|
| Response accuracy | Baseline | +23.4% improvement |
| Hallucination rate | 27.8% | 8.9% |
| User satisfaction | Low | Significantly higher |
| Ticket escalation rate | High | Reduced by grounding |
"Grounding AI responses in real retrieved context is not a nice-to-have for support systems. It is the mechanism that separates a useful tool from a liability."
Understanding the gap between customer service vs. experience helps clarify why accuracy matters at every touchpoint. A support interaction that delivers wrong information is not just a service failure; it actively damages the broader product experience users associate with your brand.
Essential tools and requirements for code ingestion pipelines

Before writing a single line of pipeline code, you need to understand the five stages every production RAG system moves through: ingestion, indexing, retrieval, augmentation, and generation. Each stage has distinct tooling requirements, and skipping any one of them creates gaps that surface as inaccurate answers.
A production-appropriate way to ingest source code for accurate AI support is to use a RAG-style pipeline that separates ingestion and indexing from retrieval, then grounds generation in retrieved evidence. That separation is critical because it lets you update your code index independently of the generation model.
Here is what you need at each stage:
- Ingestion layer: A code parser or AST (abstract syntax tree) extractor that reads your repository. Tools like Tree-sitter work across many languages and preserve logical structure rather than treating code as raw text.
- Chunking strategy: A splitter that respects function and class boundaries rather than splitting on fixed character counts. Semantic chunking at the function level keeps related logic together.
- Embedding model: A model fine-tuned on code, such as one from the CodeBERT family, produces better vector representations than general-purpose text embeddings for source code.
- Vector store: A database that stores embeddings and supports approximate nearest-neighbor search. Options range from open-source self-hosted solutions to fully managed cloud services.
- Lexical search layer: A keyword search engine running alongside the vector store enables hybrid retrieval, which is essential for matching exact identifiers and error strings.
- Reranker: A cross-encoder model that reorders retrieved results by relevance before they reach the generation step.
- Generation model: The LLM that produces the final support response, configured to cite its sources and refuse to answer when evidence is insufficient.
Open-source vs. managed solutions:
| Dimension | Open-source stack | Managed solution |
|---|---|---|
| Setup time | Days to weeks | Hours |
| Customization | Full control | Limited |
| Maintenance burden | High | Low |
| Cost at scale | Lower | Higher |
| Security controls | You own them | Provider-managed |
Reviewing customer feedback tools alongside your ingestion stack helps you connect the retrieval pipeline to the actual feedback signals your users generate, so the system learns from real support patterns over time.
Pro Tip: Use code-structure-aware chunking from the start. Splitting on function and class boundaries rather than token counts means each chunk carries a complete, coherent unit of logic. This dramatically improves retrieval precision because a retrieved chunk answers a specific question rather than containing half an answer and half of something unrelated. You can find additional guidance on pipeline design across helpful support articles covering AI-driven workflows.
Step-by-step guide to ingesting source code for AI support
Once tools are ready, here's exactly how to ingest code and set up the retrieval process for accurate AI support. Follow these steps in order. Skipping ahead creates silent failures that are hard to diagnose later.
Connect to your repository. Set up authenticated read access to your codebase using a service account with least-privilege permissions. Pull the full repository or the relevant modules, depending on scope.
Parse and extract logical units. Run your AST parser across all source files. Extract functions, classes, and their docstrings as discrete units. Tag each unit with metadata: file path, module name, language, last modified date, and the author if relevant for permissioning.
Chunk by structure, not size. Group code into chunks that represent complete logical units. A function with its docstring is one chunk. A class with its methods may be one chunk or several, depending on length. Treat code ingestion as production infrastructure: ingest, chunk with code-structure awareness, embed, index, hybrid retrieve, rerank, and generate with citations, then keep the index incrementally updated as the codebase and docs change.
Generate embeddings. Pass each chunk through your embedding model. Store the resulting vectors alongside the raw chunk text and metadata in your vector store.
Build the lexical index. Index the same chunks in your keyword search engine. This parallel index handles exact-match queries for error codes, function names, and class identifiers that semantic search can miss.
Configure hybrid retrieval. Code-aware ingestion improves accuracy when retrieval is hybrid, combining lexical and semantic search, and reranked, because embedding-only retrieval can miss exact identifiers and error strings. Set up your retrieval layer to query both indexes simultaneously and merge results.
Apply reranking. Pass the merged candidate chunks through your cross-encoder reranker. This step reorders results by contextual relevance to the specific support query, not just surface similarity.
Generate with grounding. Send the top-ranked chunks as context to your generation model. Instruct the model to cite specific chunks in its answer and to explicitly state when it cannot find supporting evidence rather than guessing.
Chunking strategy comparison:
| Strategy | Pros | Cons |
|---|---|---|
| Fixed token size | Simple to implement | Splits logical units mid-function |
| Sentence-based | Works well for docs | Poor fit for code syntax |
| AST-based (function/class) | Preserves logic, best retrieval | Requires language-specific parser |
| Sliding window | Captures cross-boundary context | High redundancy, larger index |
Pro Tip: Rerank retrieval results before passing them to the generation model. Without reranking, the top semantic match may be a function that uses the same variable name as the query but solves a completely different problem. A reranker trained on relevance pairs catches this and surfaces the genuinely useful chunk. You can explore additional support best practices to complement your pipeline design.

Troubleshooting and handling edge cases in code ingestion
Even with the right setup, ingestion failures can occur. Here's how to troubleshoot and maintain reliability when things go wrong.
The most common failure modes are:
- Stale index: The codebase updates but the index does not. Users ask about a new feature and the AI answers based on the old implementation. Fix this with incremental indexing triggered by your CI/CD pipeline on every merge to main.
- Chunking boundary errors: A function is split across two chunks, so neither chunk contains enough context to answer accurately. Fix this by validating chunk boundaries against your AST output before indexing.
- Missing metadata: Chunks without file path or module tags cannot be traced back to their source, making citations impossible. Fix this by enforcing metadata schema validation at ingestion time.
- Embedding model mismatch: Using a general text embedding model for code produces poor vector representations. Fix this by switching to a code-specific embedding model and re-indexing.
- Permissioning gaps: Internal or restricted code modules get ingested alongside public-facing code. Fix this by applying least-privilege access controls at the ingestion layer, so the retrieval system only surfaces code the support context is authorized to reference.
One critical edge case is retrieval failure due to stale or incomplete knowledge and chunking issues. Systems need mechanisms to prevent confident responses without evidence and to update indexes as code changes.
Additional edge cases to plan for include permissioned code visibility using least-privilege retrieval, near-duplicate or training-noise in retrieved passages, and "no-result" situations where the system must escalate or refuse rather than guess.
"An AI support system that says 'I don't have enough information to answer this accurately' is far more trustworthy than one that invents a plausible-sounding answer. Build the refusal path before you build anything else."
The difference in customer support between a system that escalates gracefully and one that hallucinates confidently is enormous in practice. Teams that build explicit escalation paths into their pipelines see fewer compounding errors and faster resolution times. When retrieval returns no results above your confidence threshold, route the query to a human agent rather than letting the model speculate. Grounded support responses that cite actual code are the standard to hold every AI answer to.
Evaluating pipeline accuracy: Metrics and ongoing verification
Finally, maintaining high support accuracy requires robust evaluation. Here's how to measure and verify your pipeline over time.
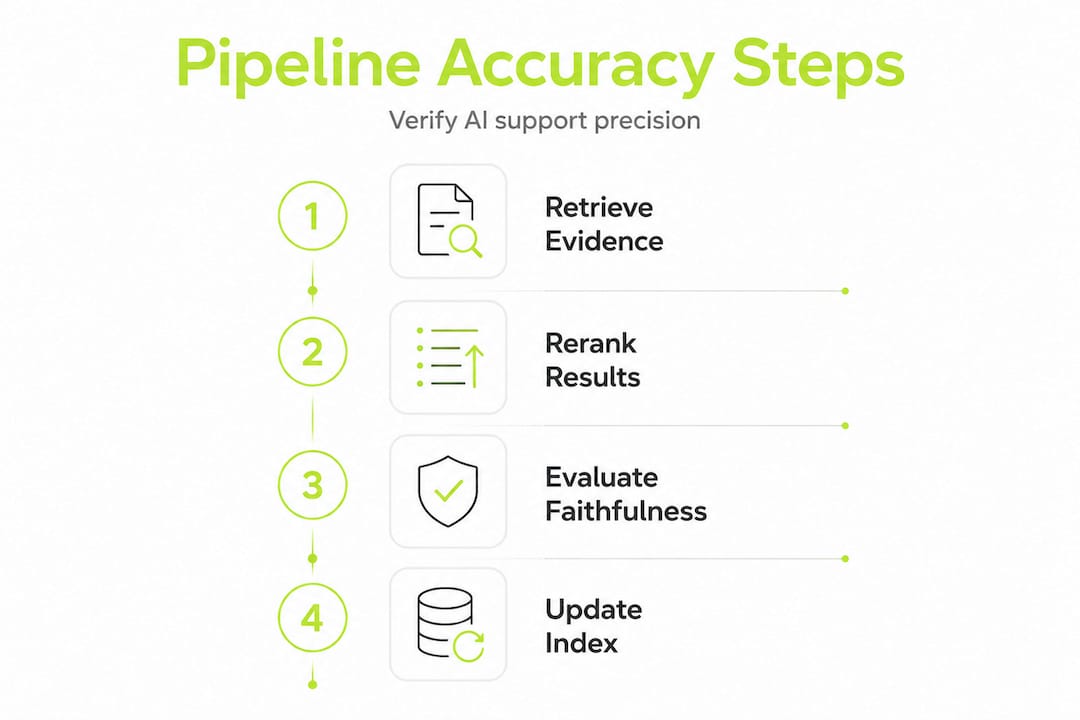
Evaluation should measure both retrieval quality and answer faithfulness and grounding, not just generation quality. Teams that only measure whether the generated answer sounds good miss the more important question: was it actually supported by the retrieved evidence?
The metrics that matter most:
- Retrieval precision at K: Of the top K chunks retrieved, what percentage were actually relevant to the query? This tells you whether your hybrid retrieval and reranking are working.
- Retrieval recall: Did the system surface all the relevant chunks that existed in the index? Low recall means users get incomplete answers even when the information is available.
- Answer faithfulness score: Does every claim in the generated answer map back to a specific retrieved chunk? This is the core grounding metric.
- Evidence hit rate: What percentage of incoming support queries return at least one relevant chunk above your confidence threshold? A low hit rate signals index coverage gaps.
- Grounded answer rate: What percentage of final answers include at least one cited source? This is your operational baseline for accountability.
- Hallucination rate: Spot-check a sample of answers weekly. Flag any claim not traceable to a retrieved chunk. Track this over time as your codebase evolves.
Run end-to-end evaluations on a labeled test set that covers your most common support query types. Include queries that should return no results, to verify your refusal path works correctly. Revisit customer feedback metrics alongside pipeline metrics to connect technical accuracy to real user satisfaction signals.
A practical cadence: run automated retrieval and faithfulness checks on every index update, and run full end-to-end evaluations monthly or after major codebase changes.
Why retrieval and grounding matter more than model size
Most teams chasing better AI support accuracy reach for the same lever first: upgrade to a larger or newer language model. It feels intuitive. Bigger model, smarter answers. But this framing misses where the actual failures are happening.
In nearly every production support scenario we've seen, the bottleneck is not the model's reasoning capability. It's what the model has access to when it generates an answer. A GPT-4-class model with no relevant code context will hallucinate. A smaller, cheaper model with precise, well-retrieved code chunks will answer accurately. The retrieval and grounding layer is doing the real work.
Improvements usually come from the retrieval and grounding layer more than raw model size. If you benchmark only retrieval or only generation, you may overestimate end-to-end accuracy and underestimate operational failure modes. This is the part most teams get wrong. They run isolated benchmarks on generation quality, see good scores, and ship. Then real-world failure rates are much higher because the retrieval layer was never stress-tested against the actual query distribution.
The uncomfortable truth is that model scaling is expensive and has diminishing returns for support accuracy. Retrieval engineering is cheaper, more targeted, and produces measurable gains on the specific queries your users actually ask. Investing in hybrid retrieval, reranking, and incremental index updates delivers more support accuracy per dollar than any model upgrade.
Building faithful customer support means designing systems where every answer is traceable to evidence. That discipline starts at the retrieval layer, not the generation layer.
Get started with accurate, AI-powered support
Applying everything in this guide requires tooling that connects your codebase to your support workflow without forcing your team to build and maintain a custom pipeline from scratch.
Coevy is built for exactly this. The platform's AI customer support solutions go beyond documentation-based AI by reading your actual source code, so support responses are grounded in what your application genuinely does right now, not what a training dataset assumed it does. Features like auto-tagging, session replays, and AI-generated reproduction steps work together to give your team the full context needed for fast, accurate resolution. Explore support workflow insights to see how teams are already using codebase-aware AI to cut ticket cycles and improve user trust.
Frequently asked questions
What is the best way to ingest source code for AI support accuracy?
A production-appropriate way to ingest source code for accurate AI support is to use a RAG-style pipeline that separates ingestion, indexing, retrieval, augmentation, and grounded generation. This structure ensures answers are always tied to real evidence from your codebase.
How does hybrid retrieval improve AI coding support?
Code-aware ingestion improves accuracy when retrieval combines semantic and lexical search, because embedding-only retrieval can miss exact identifiers and error strings that keyword search catches precisely.
How should support teams handle stale or incomplete code ingestion?
Systems need mechanisms to prevent confident responses without evidence and to update indexes as code changes. Trigger incremental re-indexing from your CI/CD pipeline on every codebase merge to keep the knowledge current.
What metrics should be used to evaluate support pipeline accuracy?
Evaluation should measure both retrieval quality and answer faithfulness and grounding, not just generation quality. Track evidence hit rate and grounded answer rate as your primary operational metrics.
Why does grounding reduce hallucination rates in support answers?
Grounding can materially reduce hallucinations and improve response accuracy for customer support by anchoring every generated claim to a specific retrieved code chunk, eliminating the model's need to speculate.