
Contextual issue reporting is defined as the practice of combining structured metadata, narrative context, and communication history into a single, coherent record that gives engineers and stakeholders everything they need to understand and resolve a problem. The best examples of contextual issue reporting show a clear pattern: teams that attach session data, role-specific commentary, and trend context to every ticket cut resolution times dramatically compared to teams relying on plain text descriptions. UK government best practice guidance confirms that combining narrative with KPIs and multi-year trend visuals helps stakeholders understand not just what happened, but why. For journalists, researchers, and software professionals, understanding these methods is the difference between reports that drive action and reports that collect dust.
1. Examples of contextual issue reporting with AI-assisted triage
AI-assisted triage is one of the most documented and measurable forms of contextual issue reporting. In a fast-paced R&D environment, bug evaluation time dropped 93% from 30 minutes per ticket to just 2 minutes after implementing an AI-assisted triage workflow. That figure reflects what happens when an AI system reads full issue context, including historical comments, metadata, and prior resolutions, rather than treating each ticket as an isolated event.

The workflow also reduced ineffective communication by 40%. That reduction matters because most of the friction in bug resolution comes not from the bug itself, but from teams arguing over subjective interpretations of the same report.
A key mechanism in this approach is the Identity Recognition Loop. This technique distinguishes developers from testers within the same ticket thread, separating technical root-cause analysis from user-impact observations. The result is a more objective report that removes the back-and-forth between roles and surfaces the most relevant context for whoever is making the fix.
- The AI reads complete ticket history, not just the most recent comment.
- Role labels are applied automatically, so developer input and tester input are weighted differently.
- Historical patterns from similar bugs are surfaced alongside the current ticket.
- Triage decisions are logged with reasoning, creating an auditable trail.
Pro Tip: When setting up AI-assisted triage, tag every ticket with a role field at submission. Without role metadata, the Identity Recognition Loop cannot separate technical from experiential feedback, and the AI defaults to treating all comments equally.
2. How data engineering shapes contextual reporting for AI agents
Raw API access is not enough to make AI reporting agents reliable. Context engineering involves curating data access, metric definitions, and fallback strategies so that AI agents receive a structured, trustworthy layer of information rather than a raw data dump. The distinction is significant. An AI agent reading raw API output has no way to know which metric formula applies, what the acceptable fallback is when data is missing, or how a given number relates to business goals.
A concrete example comes from Google Ads campaign reporting. When an AI agent is given only raw impression and click data, it produces surface-level summaries. When the same agent receives a curated data model that includes cost-per-acquisition targets, historical benchmarks, and explicit definitions for conversion events, its output shifts from description to diagnosis. That shift is the core value of context engineering in issue reporting.
Effective curated data layers include:
- Explicit metric formulas with defined numerators and denominators.
- Fallback strategies for when primary data sources are unavailable.
- Business rule annotations that explain what a metric means in context.
- Confidence scores that flag when the AI is working with incomplete data.
Reporting frameworks must evolve from static metrics to narrative-driven insights benchmarked against industry standards. Teams that treat data engineering as a reporting discipline, not just an infrastructure task, consistently produce AI outputs that stakeholders can act on.
3. Integrated communication systems in automated incident reporting
Automated incident reporting fails when information lives in separate systems. The most effective contextual reporting examples from 2026 show teams that synchronize Slack transcripts, ITSM tickets, and monitoring alerts into a single, unified context log. Synchronizing multiple communication sources prevents information silos and dramatically shortens the time any engineer needs to get up to speed on an active incident.
The measurable impact of this approach is significant. An e-commerce platform reduced MTTR from 3 hours to 22 minutes by implementing AI-driven workflows that correlate logs, tickets, and communications into cohesive reports. That is an 8x reduction in Mean Time to Resolution. The gain came not from faster engineers, but from eliminating the time spent hunting for context across disconnected tools.
The steps that produce this outcome follow a clear sequence:
- All communication channels are connected to a central incident log at the moment an alert fires.
- The system tags each entry with a timestamp, source, and author role.
- AI correlates entries across channels to identify causal chains.
- A unified summary is generated and attached to the ITSM ticket automatically.
- Engineers joining the investigation receive a structured briefing, not a raw chat log.
Pro Tip: Build the unified log before you need it. Teams that configure channel integrations during an active incident lose the first 20 minutes of context. Set up the synchronization in advance so every alert automatically triggers a complete record from the first second.
4. Crash metadata integration as a contextual reporting case study
Structured crash metadata is one of the clearest issue reporting case studies available. An engineering team managing Unreal Engine crashes cut resolution time from 2 hours to 20 minutes by integrating automated crash metadata directly into development workflows. That 83% reduction came from attaching stack traces, build versions, hardware configurations, and session state to every crash report automatically.
The key insight is that the metadata did not replace human judgment. It replaced the time engineers spent gathering information before they could apply judgment. When every crash report arrives with a complete context package, the engineer's first action is analysis, not investigation setup.
This approach applies directly to AI-generated reproduction steps for bugs. When session data is attached automatically, AI systems can generate accurate reproduction sequences without requiring the reporter to manually reconstruct what happened. The reporter describes the symptom. The system provides the context.
5. Best practices for reporting issues: avoiding context poisoning
Context poisoning is the single most common failure mode in AI-assisted issue reporting. Dumping unrelated files into AI workflows buries the relevant signal under noise and causes the AI to generate confused or incorrect patches. The problem is not that the AI lacks capability. The problem is that it receives too much irrelevant information and cannot distinguish signal from background.
Practitioners avoid context poisoning through deliberate curation. The goal is to give the AI exactly what it needs and nothing more.
"Including entire source trees leads to signal buried under noise and incorrect patches." This principle applies equally to bug reports, incident logs, and analytical reports. More data is not better data.
Effective curation practices include:
- Including only the files directly related to the reported issue.
- Prioritizing stack traces over full log dumps.
- Removing stale context from AI chat sessions before starting a new investigation.
- Defining a clear "done state" so the AI knows when the issue is resolved and stops generating additional suggestions.
- Reviewing AI output for signs of confusion, such as fixes that address unrelated code paths.
Teams that apply AI tagging to categorize feedback before it enters the reporting pipeline reduce context poisoning risk significantly. Tagging forces categorization at submission, which means the AI receives pre-filtered, relevant context rather than a raw feed.
6. Narrative and trend context in stakeholder-facing reports
Stakeholder reports fail when they present numbers without explanation. Narrative and trend data together support clearer interpretation, helping stakeholders understand not only what happened, but why it did. A KPI without a trend line is a data point. A KPI with a three-year trend, an annotated anomaly, and a one-paragraph explanation is a contextual report.
The practical difference shows up in decision-making speed. When a stakeholder can read a report and immediately understand the cause of a performance change, they can approve a fix or redirect resources without a follow-up meeting. That efficiency compounds across every reporting cycle.
For software teams, this means every issue report should include a brief narrative summary alongside the structured data. The summary answers three questions: what changed, when it changed, and what the likely cause is. The structured data provides the evidence. The narrative provides the interpretation. Together, they form a complete contextual report that any stakeholder can act on without additional briefing.
Key takeaways
The most effective contextual issue reporting combines structured metadata, role-aware AI triage, curated data layers, and narrative summaries to cut resolution time and reduce communication friction across teams.
| Point | Details |
|---|---|
| AI triage cuts resolution time | AI-assisted triage reduced bug evaluation from 30 minutes to 2 minutes per ticket in documented R&D cases. |
| Curated data beats raw access | Context engineering with metric formulas and fallback strategies produces more accurate AI reporting than raw API feeds. |
| Unified logs speed investigations | Synchronizing Slack, ITSM, and monitoring alerts into one log reduced MTTR from 3 hours to 22 minutes in one case. |
| Context poisoning degrades accuracy | Including irrelevant files in AI workflows causes incorrect outputs; curate inputs to only essential files and stack traces. |
| Narrative plus data drives decisions | Combining trend visuals with written explanation helps stakeholders act without additional briefing. |
What I've learned from watching contextual reporting evolve
The shift I find most significant is not the speed gains. Teams have always wanted faster resolution. What has actually changed is the quality of the conversation around an issue. When a report arrives with session context, role-tagged commentary, and a narrative summary, the debate about what happened essentially ends before it starts.
I have watched teams spend 45 minutes in a war room arguing about whether a crash was a code defect or a configuration error. The same argument takes about 3 minutes when the report includes a stack trace, the build version, and a log of what the user did in the 60 seconds before the crash. The context does not just speed things up. It changes the nature of the conversation entirely.
The area I think is most underrated is the Identity Recognition Loop concept. Most teams treat all ticket comments as equivalent. A tester saying "this feels broken" and a developer saying "the null pointer originates in the auth module" carry very different informational weight. AI systems that prioritize issues by code impact and role context produce dramatically better triage decisions than systems that treat every comment as equal text.
My practical recommendation: start with the data layer before you add AI. Teams that deploy AI reporting agents on top of poorly structured data get confident-sounding outputs that are frequently wrong. Fix the context first. The AI performance follows.
— Dizzy
Coevy captures the context your team needs at the moment it matters
Software teams lose hours every week reconstructing what happened before a bug was reported. Coevy solves that problem by capturing session replays, user actions, and system state automatically at the moment a user submits feedback, so your team receives a complete context package with every ticket.
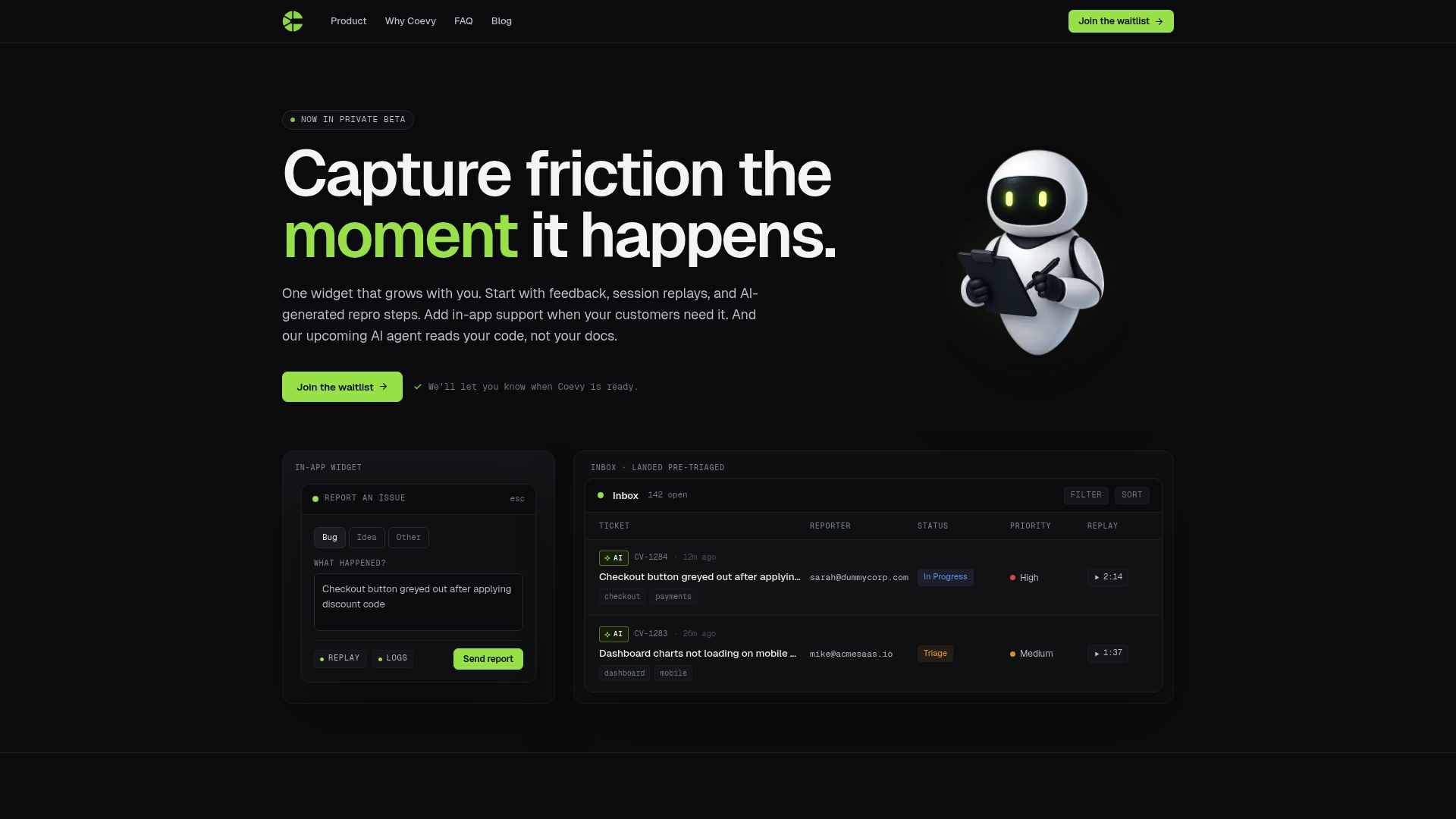
Coevy's AI-powered features include auto-tagging, prioritization, and codebase-aware assistance that reads your actual source code rather than relying on documentation. That means the context attached to every issue is grounded in your real application state, not a generic summary. Teams using Coevy spend less time gathering information and more time fixing problems. Visit Coevy to see how contextual issue capture works in practice.
FAQ
What is contextual issue reporting?
Contextual issue reporting is the practice of attaching structured metadata, session history, and narrative explanation to every issue record. It gives engineers and stakeholders the full picture of what happened, when, and why, without requiring follow-up questions.
How does AI-assisted triage improve issue reporting?
AI-assisted triage reads complete ticket history, applies role labels, and surfaces related past issues automatically. In one documented R&D case, this approach cut bug evaluation time by 93% and reduced communication friction by 40%.
What is context poisoning in issue reporting?
Context poisoning occurs when irrelevant or excessive data is fed into an AI workflow, causing the system to generate inaccurate or off-target outputs. The fix is deliberate curation: include only the files, stack traces, and logs directly relevant to the issue.
Why does narrative context matter in technical reports?
Narrative context explains the cause behind the numbers, which is what stakeholders need to make decisions. A metric without explanation is a data point. A metric with a trend line and a written summary is a report that drives action.
How does Coevy support contextual issue reporting?
Coevy automatically attaches session replays, user actions, and system state to every submitted ticket. Its AI features include auto-tagging and codebase-aware prioritization, which means teams receive structured, context-rich reports without requiring reporters to manually document what happened.